Turn A/B testing into a system that moves CAC and trial-to-paid
A/B testing only moves the business when it's tied to a metric that shows up in the P&L. The structured testing program behind Campaign Monitor's 64% CAC reduction.


A/B testing only moves the business when it's tied to a metric that shows up in the P&L, not just on the page. I run testing as a structured program built around one isolated change per test, run to 95% significance, and connected back to CAC or trial-to-paid. That discipline is how Campaign Monitor cut customer acquisition cost by 64% across 33 tests, with a cumulative CVR uplift of 1187%.
Anyone can run an A/B test. Far fewer move the needle on anything that matters.
The gap isn't the tool. Optimizely, VWO, Convert, AB Tasty – they all run experiments well. The gap is what happens around the test: how the hypothesis gets chosen, when the test gets called, and whether the win ever connects to a number a CFO cares about.
Most stalled testing programs share the same three holes. No prioritization framework, so tests get picked by whoever argues hardest in the standup. No link from page CVR to a business metric like CAC, so a 20% lift on a page nobody monetizes gets celebrated as a win. And no system for capturing what a loss taught you, so the same dead ends get retested six months later.
Here's the loop I run to close all three.
One hypothesis · One result
Find the friction
Heatmaps, session recordings, funnel data. Before a single variant is built, I want to see where visitors actually drop off, not where someone assumes they drop off. The hypothesis comes from the data, not from a deck.
On a paid funnel, the first test is almost always one of three categories: message match between the ad and the landing page, CTA clarity, or form friction. Those three produce the largest CAC drop per dev hour, because they're the friction most teams have never actually tested.
Design one isolated change
One control, one challenger, one variable. The success metric and the kill criterion both get written before the test goes live, not negotiated afterward when the data is ambiguous, and everyone wants their preferred version to win.
This is the part that feels slow and saves you from yourself. When the rule exists before the result, nobody gets to move the goalposts once the numbers land.
Run to significance, never early
95% is the default. 90% for directional tests, where being wrong is cheap, 99% for pricing or revenue-critical changes, where being wrong is expensive. The threshold is a decision per test, not a constant you set once and forget.
As a rule of thumb, that means at least 1,000 conversions per variant and two full business cycles, usually a minimum of two weeks. Calling a test early because the line jumped on a Friday is the most common mistake in CRO, and the fastest way to ship a winner that quietly disappears the moment you scale ad spend.
If a test doesn't reach significance, it's reported as inconclusive. No winner pill, no story bolted on afterward. Calling a flat test a win is the quickest way to lose the trust of the team relying on the data.
Ship the winner, keep the loss
The winner becomes the next test's control, so the baseline only ever moves up. The loss isn't discarded either – it reshapes the next hypothesis, so the program learns rather than looping on the same ideas.
Same four steps on every test, every client, every page.
Why this show up in the P&L
CVR on a page is easy to lift out of context. The discipline is connecting every test to a metric that survives contact with the business.
For Campaign Monitor, which started with message match. Their automated ads were landing on a page featuring a generic "elegantly simple email marketing" headline. The challenger restated the ad's automation promise word-for-word above the fold. Same traffic, same offer, same form, only the message changed. Conversion rate went from 2.33% to 5.87%, a 152.5% lift at full significance.
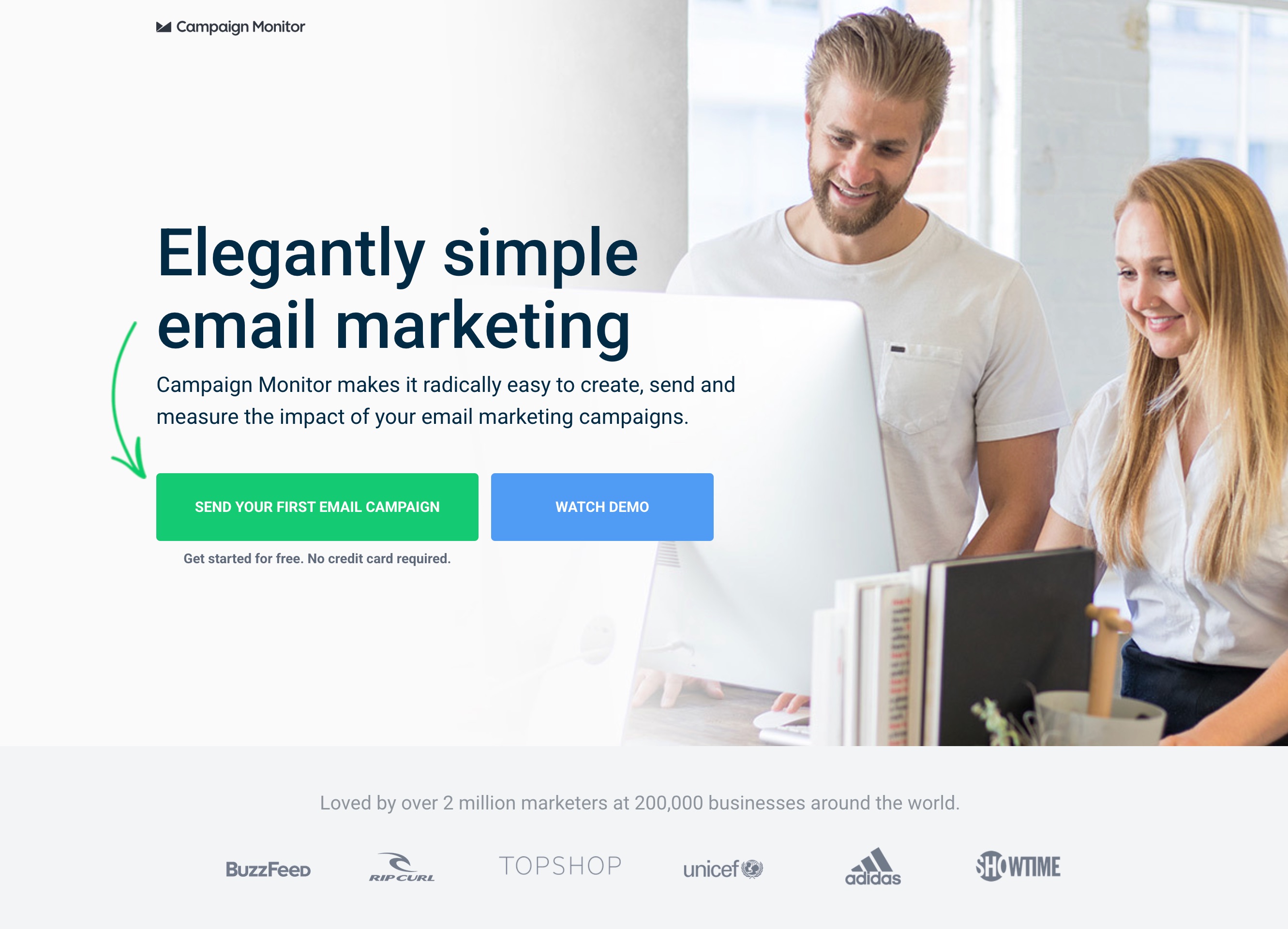
Elegantly simple email marketing
Generic value proposition with no direct match to the automation ad copy driving traffic.
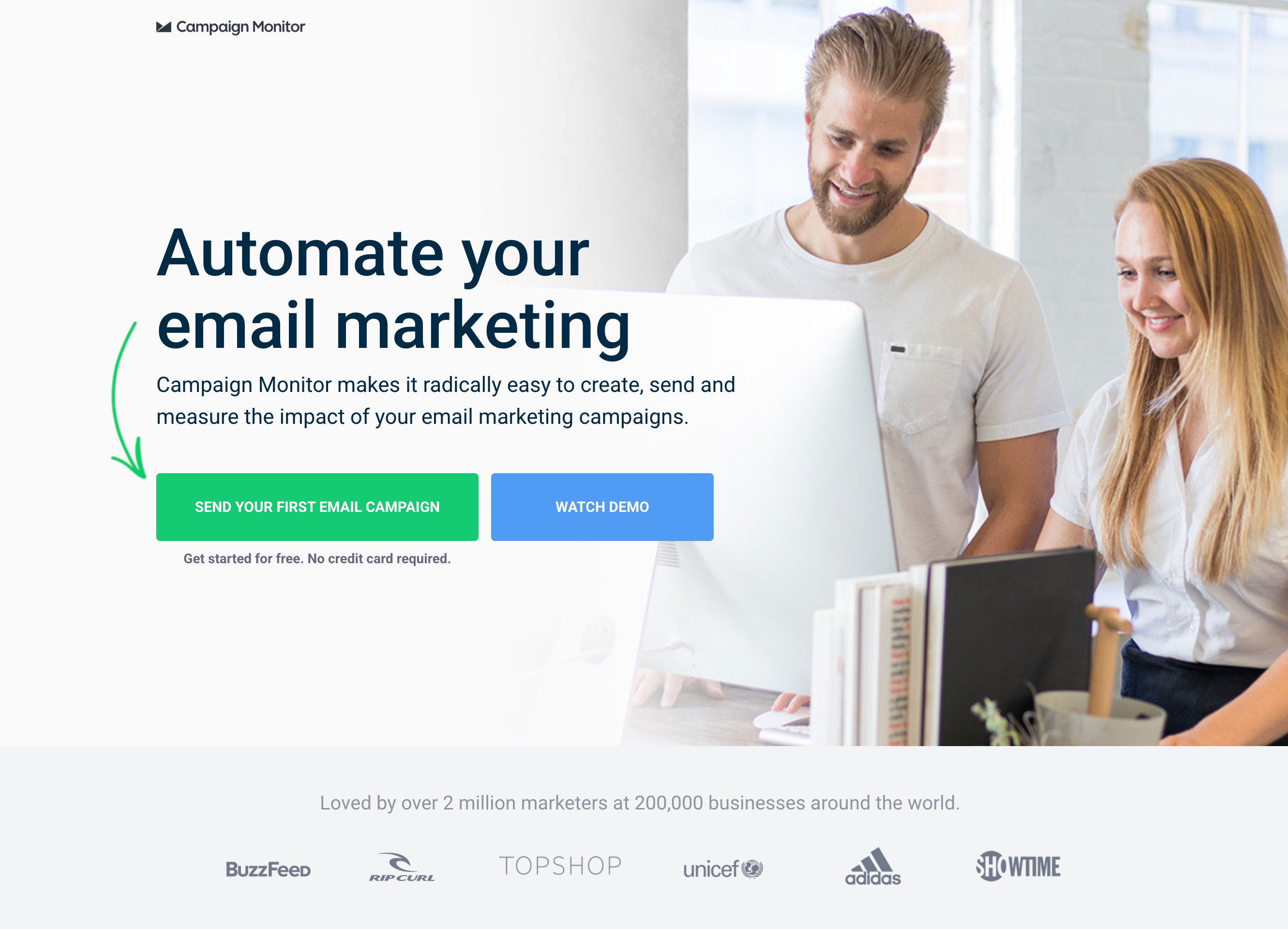
Automate your email marketing
Headline matches the ad's automation promise. Visitor's mental thread from ad to page stays unbroken.
"We increased conversion rates by 1187% cumulatively across the full engagement, and saw a 64% reduction in customer acquisition cost."
– Shamita Jayakumar, Senior Marketing Manager, Campaign Monitor
The ad budget stayed flat. Cost per acquisition dropped because every winning test pulled more trials out of the same spend. That's the difference between a page metric and a business metric: one looks good in a screenshot, the other is still paying out three quarters later. The same discipline applies inside the funnel – BetterWorld's signup page increased trial signups by 204% from one layout simplification test.
Not every test wins, and that's the point. A program where everything wins is a program testing things that were never the friction. The bar is whether the win shows up where the business actually counts it.
See the full method: conversionlab.no/method/